Training Deep Neural Networks
Tutorials
Popular Training Approaches of DNNs — A Quick Overview
Optimisation and training techniques for deep learning
https://blog.acolyer.org/2017/03/01/optimisation-and-training-techniques-for-deep-learning/
Activation functions
ReLU
Rectified linear units improve restricted boltzmann machines
- intro: ReLU
- paper: http://machinelearning.wustl.edu/mlpapers/paper_files/icml2010_NairH10.pdf
Expressiveness of Rectifier Networks
- intro: ICML 2016
- intro: This paper studies the expressiveness of ReLU Networks
- arxiv: https://arxiv.org/abs/1511.05678
How can a deep neural network with ReLU activations in its hidden layers approximate any function?
Understanding Deep Neural Networks with Rectified Linear Units
- intro: Johns Hopkins University
- arxiv: https://arxiv.org/abs/1611.01491
Learning ReLUs via Gradient Descent
https://arxiv.org/abs/1705.04591
Training Better CNNs Requires to Rethink ReLU
https://arxiv.org/abs/1709.06247
Deep Learning using Rectified Linear Units (ReLU)
- intro: Adamson University
- arxiv: https://arxiv.org/abs/1803.08375
- github: https://github.com/AFAgarap/relu-classifier
LReLU
Rectifier Nonlinearities Improve Neural Network Acoustic Models
- intro: leaky-ReLU, aka LReLU
- paper: http://ai.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf
Deep Sparse Rectifier Neural Networks
PReLU
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
- keywords: PReLU, Caffe “msra” weights initilization
- arxiv: http://arxiv.org/abs/1502.01852
Empirical Evaluation of Rectified Activations in Convolutional Network
- intro: ReLU / LReLU / PReLU / RReLU
- arxiv: http://arxiv.org/abs/1505.00853
SReLU
Deep Learning with S-shaped Rectified Linear Activation Units
- intro: SReLU
- arxiv: http://arxiv.org/abs/1512.07030
Parametric Activation Pools greatly increase performance and consistency in ConvNets
From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification
- intro: ICML 2016
- arxiv: http://arxiv.org/abs/1602.02068
- github: https://github.com/gokceneraslan/SparseMax.torch
- github: https://github.com/Unbabel/sparsemax
Revise Saturated Activation Functions
Noisy Activation Functions
MBA
Multi-Bias Non-linear Activation in Deep Neural Networks
- intro: MBA
- arxiv: https://arxiv.org/abs/1604.00676
Learning activation functions from data using cubic spline interpolation
- arxiv: http://arxiv.org/abs/1605.05509
- bitbucket: https://bitbucket.org/ispamm/spline-nn
What is the role of the activation function in a neural network?
Concatenated ReLU (CRelu)
Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units
- intro: ICML 2016
- arxiv: http://arxiv.org/abs/1603.05201
Implement CReLU (Concatenated ReLU)
GELU
Bridging Nonlinearities and Stochastic Regularizers with Gaussian Error Linear Units
Formulating The ReLU
Activation Ensembles for Deep Neural Networks
https://arxiv.org/abs/1702.07790
SELU
Self-Normalizing Neural Networks
- intro: SELU
- arxiv: https://arxiv.org/abs/1706.02515
- github: https://github.com/bioinf-jku/SNNs
- notes: https://github.com/kevinzakka/research-paper-notes/blob/master/snn.md
- github(Chainer): https://github.com/musyoku/self-normalizing-networks
SELUs (scaled exponential linear units) - Visualized and Histogramed Comparisons among ReLU and Leaky ReLU
https://github.com/shaohua0116/Activation-Visualization-Histogram
Difference Between Softmax Function and Sigmoid Function
http://dataaspirant.com/2017/03/07/difference-between-softmax-function-and-sigmoid-function/
Flexible Rectified Linear Units for Improving Convolutional Neural Networks
- keywords: flexible rectified linear unit (FReLU)
- arxiv: https://arxiv.org/abs/1706.08098
Be Careful What You Backpropagate: A Case For Linear Output Activations & Gradient Boosting
- intro: CMU
- arxiv: https://arxiv.org/abs/1707.04199
EraseReLU
EraseReLU: A Simple Way to Ease the Training of Deep Convolution Neural Networks
https://arxiv.org/abs/1709.07634
Swish
Swish: a Self-Gated Activation Function
Searching for Activation Functions
- intro: Google Brain
- arxiv: https://arxiv.org/abs/1710.05941
- reddit: https://www.reddit.com/r/MachineLearning/comments/77gcrv/d_swish_is_not_performing_very_well/
Deep Learning with Data Dependent Implicit Activation Function
https://arxiv.org/abs/1802.00168
Series on Initialization of Weights for DNN
Initialization Of Feedfoward Networks
Initialization Of Deep Feedfoward Networks
Initialization Of Deep Networks Case of Rectifiers
Weights Initialization
An Explanation of Xavier Initialization
Random Walk Initialization for Training Very Deep Feedforward Networks
Deep Neural Networks with Random Gaussian Weights: A Universal Classification Strategy?
All you need is a good init
- intro: ICLR 2016
- intro: Layer-sequential unit-variance (LSUV) initialization
- arxiv: http://arxiv.org/abs/1511.06422
- github(Caffe): https://github.com/ducha-aiki/LSUVinit
- github(Torch): https://github.com/yobibyte/torch-lsuv
- github: https://github.com/yobibyte/yobiblog/blob/master/posts/all-you-need-is-a-good-init.md
- github(Keras): https://github.com/ducha-aiki/LSUV-keras
- review: http://www.erogol.com/need-good-init/
All You Need is Beyond a Good Init: Exploring Better Solution for Training Extremely Deep Convolutional Neural Networks with Orthonormality and Modulation
- intro: CVPR 2017. HIKVision
- arxiv: https://arxiv.org/abs/1703.01827
Data-dependent Initializations of Convolutional Neural Networks
What are good initial weights in a neural network?
- stackexchange: http://stats.stackexchange.com/questions/47590/what-are-good-initial-weights-in-a-neural-network
RandomOut: Using a convolutional gradient norm to win The Filter Lottery
Categorical Reparameterization with Gumbel-Softmax
- intro: Google Brain & University of Cambridge & Stanford University
- arxiv: https://arxiv.org/abs/1611.01144
- github: https://github.com/ericjang/gumbel-softmax
On weight initialization in deep neural networks
Batch Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- intro: ImageNet top-5 error: 4.82%
- keywords: internal covariate shift problem
- arxiv: http://arxiv.org/abs/1502.03167
- blog: https://standardfrancis.wordpress.com/2015/04/16/batch-normalization/
- notes: http://blog.csdn.net/happynear/article/details/44238541
Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
- arxiv: http://arxiv.org/abs/1602.07868
- github(Lasagne): https://github.com/TimSalimans/weight_norm
- github: https://github.com/openai/weightnorm
- notes: http://www.erogol.com/my-notes-weight-normalization/
Normalization Propagation: A Parametric Technique for Removing Internal Covariate Shift in Deep Networks
Revisiting Batch Normalization For Practical Domain Adaptation
- intro: Pattern Recognition
- keywords: Adaptive Batch Normalization (AdaBN)
- arxiv: https://arxiv.org/abs/1603.04779
Implementing Batch Normalization in Tensorflow
Deriving the Gradient for the Backward Pass of Batch Normalization
Exploring Normalization in Deep Residual Networks with Concatenated Rectified Linear Units
- intro: Oculus VR & Facebook & NEC Labs America
- paper: https://research.fb.com/publications/exploring-normalization-in-deep-residual-networks-with-concatenated-rectified-linear-units/
Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models
- intro: Sergey Ioffe, Google
- arxiv: https://arxiv.org/abs/1702.03275
Comparison of Batch Normalization and Weight Normalization Algorithms for the Large-scale Image Classification
https://arxiv.org/abs/1709.08145
In-Place Activated BatchNorm for Memory-Optimized Training of DNNs
- intro: Mapillary Research
- arxiv: https://arxiv.org/abs/1712.02616
- github: https://github.com/mapillary/inplace_abn
Batch Kalman Normalization: Towards Training Deep Neural Networks with Micro-Batches
https://arxiv.org/abs/1802.03133
Decorrelated Batch Normalization
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1804.08450
- github: https://github.com/umich-vl/DecorrelatedBN
Backward pass of BN
Understanding the backward pass through Batch Normalization Layer
Deriving the Gradient for the Backward Pass of Batch Normalization
https://kevinzakka.github.io/2016/09/14/batch_normalization/
What does the gradient flowing through batch normalization looks like ?
http://cthorey.github.io./backpropagation/
Layer Normalization
Layer Normalization
- arxiv: https://arxiv.org/abs/1607.06450
- github: https://github.com/ryankiros/layer-norm
- github(TensorFlow): https://github.com/pbhatia243/tf-layer-norm
- github: https://github.com/MycChiu/fast-LayerNorm-TF
Keras GRU with Layer Normalization
Cosine Normalization: Using Cosine Similarity Instead of Dot Product in Neural Networks
Group Normalization
Group Normalization
- intro: Facebook AI Research (FAIR)
- arxiv: https://arxiv.org/abs/1803.08494
Loss Function
The Loss Surfaces of Multilayer Networks
Direct Loss Minimization for Training Deep Neural Nets
Nonconvex Loss Functions for Classifiers and Deep Networks
Learning Deep Embeddings with Histogram Loss
Large-Margin Softmax Loss for Convolutional Neural Networks
- intro: ICML 2016
- intro: Peking University & South China University of Technology & CMU & Shenzhen University
- arxiv: https://arxiv.org/abs/1612.02295
- github(Official. Caffe): https://github.com/wy1iu/LargeMargin_Softmax_Loss
- github: https://github.com/luoyetx/mx-lsoftmax
- github: https://github.com/tpys/face-recognition-caffe2
- github: https://github.com/jihunchoi/lsoftmax-pytorch
An empirical analysis of the optimization of deep network loss surfaces
https://arxiv.org/abs/1612.04010
Towards Understanding Generalization of Deep Learning: Perspective of Loss Landscapes
- intro: Peking University
- arxiv: https://arxiv.org/abs/1706.10239
Hierarchical Softmax
http://building-babylon.net/2017/08/01/hierarchical-softmax/
Noisy Softmax: Improving the Generalization Ability of DCNN via Postponing the Early Softmax Saturation
- intro: CVPR 2017
- arxiv: https://arxiv.org/abs/1708.03769
DropMax: Adaptive Stochastic Softmax
- intro: UNIST & Postech & KAIST
- arxiv: https://arxiv.org/abs/1712.07834
Rethinking Feature Distribution for Loss Functions in Image Classification
- intro: CVPR 2018 spotlight
- arxiv: https://arxiv.org/abs/1803.02988
Ensemble Soft-Margin Softmax Loss for Image Classification
- intro: IJCAI 2018
- arxiv: https://arxiv.org/abs/1805.03922
Learning Rate
No More Pesky Learning Rates
- intro: Tom Schaul, Sixin Zhang, Yann LeCun
- arxiv: https://arxiv.org/abs/1206.1106
Coupling Adaptive Batch Sizes with Learning Rates
- intro: Max Planck Institute for Intelligent Systems
- intro: Tensorflow implementation of SGD with Coupled Adaptive Batch Size (CABS)
- arxiv: https://arxiv.org/abs/1612.05086
- github: https://github.com/ProbabilisticNumerics/cabs
Super-Convergence: Very Fast Training of Residual Networks Using Large Learning Rates
https://arxiv.org/abs/1708.07120
Improving the way we work with learning rate.
https://medium.com/@bushaev/improving-the-way-we-work-with-learning-rate-5e99554f163b
WNGrad: Learn the Learning Rate in Gradient Descent
- intro: University of Texas at Austin & Facebook AI Research
- arxiv: https://arxiv.org/abs/1803.02865
Convolution Filters
Non-linear Convolution Filters for CNN-based Learning
- intro: ICCV 2017
- arxiv: https://arxiv.org/abs/1708.07038
Pooling
Stochastic Pooling for Regularization of Deep Convolutional Neural Networks
- intro: ICLR 2013. Matthew D. Zeiler, Rob Fergus
- paper: http://www.matthewzeiler.com/pubs/iclr2013/iclr2013.pdf
Multi-scale Orderless Pooling of Deep Convolutional Activation Features
- intro: ECCV 2014
- intro: MOP-CNN, orderless VLAD pooling, image classification / instance-level retrieval
- arxiv: https://arxiv.org/abs/1403.1840
- paper: http://web.engr.illinois.edu/~slazebni/publications/yunchao_eccv14_mopcnn.pdf
Fractional Max-Pooling
- arxiv: https://arxiv.org/abs/1412.6071
- notes: https://gist.github.com/shagunsodhani/ccfe3134f46fd3738aa0
- github: https://github.com/torch/nn/issues/371
TI-POOLING: transformation-invariant pooling for feature learning in Convolutional Neural Networks
- intro: CVPR 2016
- paper: http://dlaptev.org/papers/Laptev16_CVPR.pdf
- github: https://github.com/dlaptev/TI-pooling
S3Pool: Pooling with Stochastic Spatial Sampling
- arxiv: https://arxiv.org/abs/1611.05138
- github(Lasagne): https://github.com/Shuangfei/s3pool
Inductive Bias of Deep Convolutional Networks through Pooling Geometry
Improved Bilinear Pooling with CNNs
https://arxiv.org/abs/1707.06772
**Learning Bag-of-Features Pooling for Deep Convolutional Neural Networks
- intro: ICCV 2017
- arxiv: https://arxiv.org/abs/1707.08105
- github: https://github.com/passalis/cbof
A new kind of pooling layer for faster and sharper convergence
- blog: https://medium.com/@singlasahil14/a-new-kind-of-pooling-layer-for-faster-and-sharper-convergence-1043c756a221
- github: https://github.com/singlasahil14/sortpool2d
Statistically Motivated Second Order Pooling
https://arxiv.org/abs/1801.07492
Detail-Preserving Pooling in Deep Networks
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1804.04076
Mini-Batch
Online Batch Selection for Faster Training of Neural Networks
- intro: Workshop paper at ICLR 2016
- arxiv: https://arxiv.org/abs/1511.06343
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
- intro: ICLR 2017
- arxiv: https://arxiv.org/abs/1609.04836
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
- intro: Facebook
- keywords: Training with 256 GPUs, minibatches of 8192
- arxiv: https://arxiv.org/abs/1706.02677
Scaling SGD Batch Size to 32K for ImageNet Training
https://arxiv.org/abs/1708.03888
ImageNet Training in 24 Minutes
https://arxiv.org/abs/1709.05011
Don’t Decay the Learning Rate, Increase the Batch Size
- intro: Google Brain
- arxiv: https://arxiv.org/abs/1711.00489
Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes
- intro: NIPS 2017 Workshop: Deep Learning at Supercomputer Scale
- arxiv: https://arxiv.org/abs/1711.04325
AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks
- intro: UC Berkeley & NVIDIA
- arxiv: https://arxiv.org/abs/1712.02029
Hessian-based Analysis of Large Batch Training and Robustness to Adversaries
- intro: UC Berkeley & University of Texas
- arxiv: https://arxiv.org/abs/1802.08241
Revisiting Small Batch Training for Deep Neural Networks
https://arxiv.org/abs/1804.07612
Optimization Methods
On Optimization Methods for Deep Learning
Invariant backpropagation: how to train a transformation-invariant neural network
A practical theory for designing very deep convolutional neural network
- kaggle: https://www.kaggle.com/c/datasciencebowl/forums/t/13166/happy-lantern-festival-report-and-code/69284
- paper: https://kaggle2.blob.core.windows.net/forum-message-attachments/69182/2287/A%20practical%20theory%20for%20designing%20very%20deep%20convolutional%20neural%20networks.pdf?sv=2012-02-12&se=2015-12-05T15%3A40%3A02Z&sr=b&sp=r&sig=kfBQKduA1pDtu837Y9Iqyrp2VYItTV0HCgOeOok9E3E%3D
- slides: http://vdisk.weibo.com/s/3nFsznjLKn
Stochastic Optimization Techniques
- intro: SGD/Momentum/NAG/Adagrad/RMSProp/Adadelta/Adam/ESGD/Adasecant/vSGD/Rprop
- blog: http://colinraffel.com/wiki/stochastic_optimization_techniques
Alec Radford’s animations for optimization algorithms
http://www.denizyuret.com/2015/03/alec-radfords-animations-for.html
Faster Asynchronous SGD (FASGD)
An overview of gradient descent optimization algorithms (★★★★★)

- arxiv: https://arxiv.org/abs/1609.04747
- blog: http://sebastianruder.com/optimizing-gradient-descent/
Exploiting the Structure: Stochastic Gradient Methods Using Raw Clusters
Writing fast asynchronous SGD/AdaGrad with RcppParallel
Quick Explanations Of Optimization Methods
Learning to learn by gradient descent by gradient descent
- intro: Google DeepMind
- arxiv: https://arxiv.org/abs/1606.04474
- github: https://github.com/deepmind/learning-to-learn
- github(TensorFlow): https://github.com/runopti/Learning-To-Learn
- github(PyTorch): https://github.com/ikostrikov/pytorch-meta-optimizer
SGDR: Stochastic Gradient Descent with Restarts
- arxiv: http://arxiv.org/abs/1608.03983
- github: https://github.com/loshchil/SGDR
The zen of gradient descent
Big Batch SGD: Automated Inference using Adaptive Batch Sizes
Improving Stochastic Gradient Descent with Feedback
- arxiv: https://arxiv.org/abs/1611.01505
- github: https://github.com/jayanthkoushik/sgd-feedback
- github: https://github.com/tdeboissiere/DeepLearningImplementations/tree/master/Eve
Learning Gradient Descent: Better Generalization and Longer Horizons
- intro: Tsinghua University
- arxiv: https://arxiv.org/abs/1703.03633
- github(TensorFlow): https://github.com/vfleaking/rnnprop
Optimization Algorithms
- blog: https://3dbabove.com/2017/11/14/optimizationalgorithms/
- github: https://github.com//ManuelGonzalezRivero/3dbabove
- reddit: https://www.reddit.com/r/MachineLearning/comments/7ehxky/d_optimization_algorithms_math_and_code/
Gradient Normalization & Depth Based Decay For Deep Learning
- intro: Columbia University
- arxiv: https://arxiv.org/abs/1712.03607
Neumann Optimizer: A Practical Optimization Algorithm for Deep Neural Networks
- intro: Google Research
- arxiv: https://arxiv.org/abs/1712.03298
Optimization for Deep Learning Highlights in 2017
http://ruder.io/deep-learning-optimization-2017/index.html
Gradients explode - Deep Networks are shallow - ResNet explained
- intro: CMU & UC Berkeley
- arxiv: https://arxiv.org/abs/1712.05577
Adam
Adam: A Method for Stochastic Optimization
- intro: ICLR 2015
- arxiv: http://arxiv.org/abs/1412.6980
Fixing Weight Decay Regularization in Adam
- intro: University of Freiburg
- arxiv: https://arxiv.org/abs/1711.05101
- github: https://github.com/loshchil/AdamW-and-SGDW
- github: https://github.com/fastai/fastai/pull/46/files
Tensor Methods
Tensorizing Neural Networks
- intro: TensorNet
- arxiv: http://arxiv.org/abs/1509.06569
- github(Matlab+Theano+Lasagne): https://github.com/Bihaqo/TensorNet
- github(TensorFlow): https://github.com/timgaripov/TensorNet-TF
Tensor methods for training neural networks
- homepage: http://newport.eecs.uci.edu/anandkumar/#home
- youtube: https://www.youtube.com/watch?v=B4YvhcGaafw
- slides: http://newport.eecs.uci.edu/anandkumar/slides/Strata-NY.pdf
- talks: http://newport.eecs.uci.edu/anandkumar/#talks
Regularization
DisturbLabel: Regularizing CNN on the Loss Layer
- intro: University of California & MSR 2016
- intro: “an extremely simple algorithm which randomly replaces a part of labels as incorrect values in each iteration”
- paper: http://research.microsoft.com/en-us/um/people/jingdw/pubs/cvpr16-disturblabel.pdf
Robust Convolutional Neural Networks under Adversarial Noise
- intro: ICLR 2016
- arxiv: http://arxiv.org/abs/1511.06306
Adding Gradient Noise Improves Learning for Very Deep Networks
- intro: ICLR 2016
- arxiv: http://arxiv.org/abs/1511.06807
Stochastic Function Norm Regularization of Deep Networks
- arxiv: http://arxiv.org/abs/1605.09085
- github: https://github.com/AmalRT/DNN_Reg
SoftTarget Regularization: An Effective Technique to Reduce Over-Fitting in Neural Networks
Regularizing neural networks by penalizing confident predictions
- intro: Gabriel Pereyra, George Tucker, Lukasz Kaiser, Geoffrey Hinton [Google Brain
- dropbox: https://www.dropbox.com/s/8kqf4v2c9lbnvar/BayLearn%202016%20(gjt).pdf?dl=0
- mirror: https://pan.baidu.com/s/1kUUtxdl
Automatic Node Selection for Deep Neural Networks using Group Lasso Regularization
Regularization in deep learning
- blog: https://medium.com/@cristina_scheau/regularization-in-deep-learning-f649a45d6e0#.py327hkuv
- github: https://github.com/cscheau/Examples/blob/master/iris_l1_l2.py
LDMNet: Low Dimensional Manifold Regularized Neural Networks
https://arxiv.org/abs/1711.06246
Learning Sparse Neural Networks through L0 Regularization
- intro: University of Amsterdam & OpenAI
- arxiv: https://arxiv.org/abs/1712.01312
Regularization and Optimization strategies in Deep Convolutional Neural Network
https://arxiv.org/abs/1712.04711
Regularizing Deep Networks by Modeling and Predicting Label Structure
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1804.02009
Dropout
Improving neural networks by preventing co-adaptation of feature detectors
- intro: Dropout
- arxiv: http://arxiv.org/abs/1207.0580
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Fast dropout training
- paper: http://jmlr.org/proceedings/papers/v28/wang13a.pdf
- github: https://github.com/sidaw/fastdropout
Dropout as data augmentation
- paper: http://arxiv.org/abs/1506.08700
- notes: https://www.evernote.com/shard/s189/sh/ef0c3302-21a4-40d7-b8b4-1c65b8ebb1c9/24ff553fcfb70a27d61ff003df75b5a9
A Theoretically Grounded Application of Dropout in Recurrent Neural Networks
Improved Dropout for Shallow and Deep Learning
Dropout Regularization in Deep Learning Models With Keras
Dropout with Expectation-linear Regularization
Dropout with Theano
- blog: http://rishy.github.io/ml/2016/10/12/dropout-with-theano/
- ipn: http://nbviewer.jupyter.org/github/rishy/rishy.github.io/blob/master/ipy_notebooks/Dropout-Theano.ipynb
Information Dropout: learning optimal representations through noise
Recent Developments in Dropout
Generalized Dropout
Analysis of Dropout
Variational Dropout Sparsifies Deep Neural Networks
Learning Deep Networks from Noisy Labels with Dropout Regularization
- intro: 2016 IEEE 16th International Conference on Data Mining
- arxiv: https://arxiv.org/abs/1705.03419
Concrete Dropout
- intro: University of Cambridge
- arxiv: https://arxiv.org/abs/1705.07832
- github: https://github.com/yaringal/ConcreteDropout
Analysis of dropout learning regarded as ensemble learning
- intro: Nihon University
- arxiv: https://arxiv.org/abs/1706.06859
An Analysis of Dropout for Matrix Factorization
https://arxiv.org/abs/1710.03487
Analysis of Dropout in Online Learning
https://arxiv.org/abs/1711.03343
Regularization of Deep Neural Networks with Spectral Dropout
https://arxiv.org/abs/1711.08591
Data Dropout in Arbitrary Basis for Deep Network Regularization
https://arxiv.org/abs/1712.00891
DropConnect
Regularization of Neural Networks using DropConnect
- homepage: http://cs.nyu.edu/~wanli/dropc/
- gitxiv: http://gitxiv.com/posts/rJucpiQiDhQ7HkZoX/regularization-of-neural-networks-using-dropconnect
- github: https://github.com/iassael/torch-dropconnect
Regularizing neural networks with dropout and with DropConnect
DropNeuron
DropNeuron: Simplifying the Structure of Deep Neural Networks
Maxout
Maxout Networks
- intro: ICML 2013
- intro: “its output is the max of a set of inputs, a natural companion to dropout”
- project page: http://www-etud.iro.umontreal.ca/~goodfeli/maxout.html
- arxiv: https://arxiv.org/abs/1302.4389
- github: https://github.com/lisa-lab/pylearn2/blob/master/pylearn2/models/maxout.py
Improving Deep Neural Networks with Probabilistic Maxout Units
Swapout
Swapout: Learning an ensemble of deep architectures
- arxiv: https://arxiv.org/abs/1605.06465
- blog: https://gab41.lab41.org/lab41-reading-group-swapout-learning-an-ensemble-of-deep-architectures-e67d2b822f8a#.9r2s4c58n
Whiteout
Whiteout: Gaussian Adaptive Regularization Noise in Deep Neural Networks
- intro: University of Notre Dame & University of Science and Technology of China
- arxiv: https://arxiv.org/abs/1612.01490
ShakeDrop regularization
https://arxiv.org/abs/1802.02375
Gradient Descent
RMSProp: Divide the gradient by a running average of its recent magnitude

- intro: it was not proposed in a paper, in fact it was just introduced in a slide in Geoffrey Hinton’s Coursera class
- slides: http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
Fitting a model via closed-form equations vs. Gradient Descent vs Stochastic Gradient Descent vs Mini-Batch Learning. What is the difference?(Normal Equations vs. GD vs. SGD vs. MB-GD)
http://sebastianraschka.com/faq/docs/closed-form-vs-gd.html
An Introduction to Gradient Descent in Python
Train faster, generalize better: Stability of stochastic gradient descent
A Variational Analysis of Stochastic Gradient Algorithms
The vanishing gradient problem: Oh no — an obstacle to deep learning!
Gradient Descent For Machine Learning
Revisiting Distributed Synchronous SGD
Convergence rate of gradient descent
A Robust Adaptive Stochastic Gradient Method for Deep Learning
- intro: IJCNN 2017 Accepted Paper, An extension of paper, “ADASECANT: Robust Adaptive Secant Method for Stochastic Gradient”
- intro: Universite de Montreal & University of Oxford
- arxiv: https://arxiv.org/abs/1703.00788
Accelerating Stochastic Gradient Descent
https://arxiv.org/abs/1704.08227
Gentle Introduction to the Adam Optimization Algorithm for Deep Learning
Understanding Generalization and Stochastic Gradient Descent
A Bayesian Perspective on Generalization and Stochastic Gradient Descent
- intro: Google Brain
- arxiv: https://arxiv.org/abs/1710.06451
Accelerated Gradient Descent Escapes Saddle Points Faster than Gradient Descent
- intro: UC Berkeley & Microsoft Research, India
- arxiv: https://arxiv.org/abs/1711.10456
Improving Generalization Performance by Switching from Adam to SGD
https://arxiv.org/abs/1712.07628
AdaGrad
Adaptive Subgradient Methods for Online Learning and Stochastic Optimization
ADADELTA: An Adaptive Learning Rate Method
Momentum
On the importance of initialization and momentum in deep learning
- intro: NAG: Nesterov
- paper: http://www.cs.toronto.edu/~fritz/absps/momentum.pdf
- paper: http://jmlr.org/proceedings/papers/v28/sutskever13.pdf
YellowFin and the Art of Momentum Tuning
- intro: Stanford University
- intro: auto-tuning momentum SGD optimizer
- project page: http://cs.stanford.edu/~zjian/project/YellowFin/
- arxiv: https://arxiv.org/abs/1706.03471
- github(TensorFlow): https://github.com/JianGoForIt/YellowFin https://github.com/JianGoForIt/YellowFin_Pytorch
Backpropagation
Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks
- intro: ECCV 2016. first place of ILSVRC 2015 Scene Classification Challenge
- arxiv: https://arxiv.org/abs/1512.05830
- paper: http://www.cis.pku.edu.cn/faculty/vision/zlin/Publications/2016-ECCV-RelayBP.pdf
Top-down Neural Attention by Excitation Backprop

- intro: ECCV, 2016 (oral)
- projpage: http://cs-people.bu.edu/jmzhang/excitationbp.html
- arxiv: http://arxiv.org/abs/1608.00507
- paper: http://cs-people.bu.edu/jmzhang/EB/ExcitationBackprop.pdf
- github: https://github.com/jimmie33/Caffe-ExcitationBP
Towards a Biologically Plausible Backprop
- arxiv: http://arxiv.org/abs/1602.05179
- github: https://github.com/bscellier/Towards-a-Biologically-Plausible-Backprop
Sampled Backpropagation: Training Deep and Wide Neural Networks on Large Scale, User Generated Content Using Label Sampling
The Reversible Residual Network: Backpropagation Without Storing Activations
- intro: CoRR 2017. University of Toronto
- arxiv: https://arxiv.org/abs/1707.04585
- github: https://github.com/renmengye/revnet-public
meProp: Sparsified Back Propagation for Accelerated Deep Learning with Reduced Overfitting
- intro: ICML 2017
- arxiv: https://arxiv.org/abs/1706.06197
- github: https://github.com//jklj077/meProp
Accelerate Training
Neural Networks with Few Multiplications
- intro: ICLR 2016
- arxiv: https://arxiv.org/abs/1510.03009
Acceleration of Deep Neural Network Training with Resistive Cross-Point Devices
Deep Q-Networks for Accelerating the Training of Deep Neural Networks
Omnivore: An Optimizer for Multi-device Deep Learning on CPUs and GPUs
Parallelism
One weird trick for parallelizing convolutional neural networks
- author: Alex Krizhevsky
- arxiv: http://arxiv.org/abs/1404.5997
8-Bit Approximations for Parallelism in Deep Learning (ICLR 2016)
Handling Datasets
Data Augmentation
DataAugmentation ver1.0: Image data augmentation tool for training of image recognition algorithm
Caffe-Data-Augmentation: a branc caffe with feature of Data Augmentation using a configurable stochastic combination of 7 data augmentation techniques
Image Augmentation for Deep Learning With Keras
What you need to know about data augmentation for machine learning
- intro: keras Imagegenerator
- blog: https://cartesianfaith.com/2016/10/06/what-you-need-to-know-about-data-augmentation-for-machine-learning/
HZPROC: torch data augmentation toolbox (supports affine transform)
AGA: Attribute Guided Augmentation
- intro: one-shot recognition
- arxiv: https://arxiv.org/abs/1612.02559
Accelerating Deep Learning with Multiprocess Image Augmentation in Keras
- blog: http://blog.stratospark.com/multiprocess-image-augmentation-keras.html
- github: https://github.com/stratospark/keras-multiprocess-image-data-generator
Comprehensive Data Augmentation and Sampling for Pytorch
Image augmentation for machine learning experiments.
https://github.com/aleju/imgaug
Google/inception’s data augmentation: scale and aspect ratio augmentation
https://github.com/facebook/fb.resnet.torch/blob/master/datasets/transforms.lua#L130
Caffe Augmentation Extension
- intro: Data Augmentation for Caffe
- github: https://github.com/twtygqyy/caffe-augmentation
Improving Deep Learning using Generic Data Augmentation
- intro: University of Cape Town
- arxiv: https://arxiv.org/abs/1708.06020
- github: https://github.com/webstorms/AugmentedDatasets
Augmentor: An Image Augmentation Library for Machine Learning
Learning to Compose Domain-Specific Transformations for Data Augmentation
https://arxiv.org/abs/1709.01643
Data Augmentation in Classification using GAN
https://arxiv.org/abs/1711.00648
Data Augmentation Generative Adversarial Networks
https://arxiv.org/abs/1711.04340
Random Erasing Data Augmentation
Context Augmentation for Convolutional Neural Networks
https://arxiv.org/abs/1712.01653
The Effectiveness of Data Augmentation in Image Classification using Deep Learning
https://arxiv.org/abs/1712.04621
MentorNet: Regularizing Very Deep Neural Networks on Corrupted Labels
- intro: Google Inc & Stanford University
- arxiv: https://arxiv.org/abs/1712.05055
mixup: Beyond Empirical Risk Minimization
- intro: MIT & FAIR
- arxiv: https://arxiv.org/abs/1710.09412
- github: https://github.com//leehomyc/mixup_pytorch
- github: https://github.com//unsky/mixup
mixup: Data-Dependent Data Augmentation
http://www.inference.vc/mixup-data-dependent-data-augmentation/
Data Augmentation by Pairing Samples for Images Classification
- intro: IBM Research - Tokyo
- arxiv: https://arxiv.org/abs/1801.02929
Feature Space Transfer for Data Augmentation
- keywords: eATure TransfEr Network (FATTEN)
- arxiv: https://arxiv.org/abs/1801.04356
Visual Data Augmentation through Learning
https://arxiv.org/abs/1801.06665
Data Augmentation Generative Adversarial Networks
BAGAN: Data Augmentation with Balancing GAN
https://arxiv.org/abs/1803.09655
Parallel Grid Pooling for Data Augmentation
- intro: The University of Tokyo & NTT Communications Science Laboratories
- arxiv: https://arxiv.org/abs/1803.11370
- github(Chainer): https://github.com/akitotakeki/pgp-chainer
Imbalanced Datasets
Investigation on handling Structured & Imbalanced Datasets with Deep Learning
- intro: smote resampling, cost sensitive learning
- blog: https://www.analyticsvidhya.com/blog/2016/10/investigation-on-handling-structured-imbalanced-datasets-with-deep-learning/
A systematic study of the class imbalance problem in convolutional neural networks
- intro: Duke University & Royal Institute of Technology (KTH)
- arxiv: https://arxiv.org/abs/1710.05381
Class Rectification Hard Mining for Imbalanced Deep Learning
https://arxiv.org/abs/1712.03162
Bridging the Gap: Simultaneous Fine Tuning for Data Re-Balancing
Noisy / Unlabelled Data
Data Distillation: Towards Omni-Supervised Learning
- intro: Facebook AI Research (FAIR)
- arxiv: https://arxiv.org/abs/1712.04440
Learning From Noisy Singly-labeled Data
- intro: University of Illinois Urbana Champaign & CMU & Caltech & Amazon AI
- arxiv: https://arxiv.org/abs/1712.04577
Low Numerical Precision
Training deep neural networks with low precision multiplications
- intro: ICLR 2015
- intro: Maxout networks, 10-bit activations, 12-bit parameter updates
- arxiv: http://arxiv.org/abs/1412.7024
- github: https://github.com/MatthieuCourbariaux/deep-learning-multipliers
Deep Learning with Limited Numerical Precision
- intro: ICML 2015
- arxiv: http://arxiv.org/abs/1502.02551
BinaryConnect: Training Deep Neural Networks with binary weights during propagations
- paper: http://papers.nips.cc/paper/5647-shape-and-illumination-from-shading-using-the-generic-viewpoint-assumption
- github: https://github.com/MatthieuCourbariaux/BinaryConnect
Binarized Neural Networks
BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
- arxiv: http://arxiv.org/abs/1602.02830
- github: https://github.com/MatthieuCourbariaux/BinaryNet
- github: https://github.com/codekansas/tinier-nn
Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
Distributed Training
Large Scale Distributed Systems for Training Neural Networks
- intro: By Jeff Dean & Oriol Vinyals, Google. NIPS 2015.
- slides: https://media.nips.cc/Conferences/2015/tutorialslides/Jeff-Oriol-NIPS-Tutorial-2015.pdf
- video: http://research.microsoft.com/apps/video/default.aspx?id=259564&l=i
- mirror: http://pan.baidu.com/s/1mgXV0hU
Large Scale Distributed Deep Networks
- intro: distributed CPU training, data parallelism, model parallelism
- paper: http://www.cs.toronto.edu/~ranzato/publications/DistBeliefNIPS2012_withAppendix.pdf
- slides: http://admis.fudan.edu.cn/~yfhuang/files/LSDDN_slide.pdf
Implementation of a Practical Distributed Calculation System with Browsers and JavaScript, and Application to Distributed Deep Learning
- project page: http://mil-tokyo.github.io/
- arxiv: https://arxiv.org/abs/1503.05743
SparkNet: Training Deep Networks in Spark
- arxiv: http://arxiv.org/abs/1511.06051
- github: https://github.com/amplab/SparkNet
- blog: http://www.kdnuggets.com/2015/12/spark-deep-learning-training-with-sparknet.html
A Scalable Implementation of Deep Learning on Spark
- intro: Alexander Ulanov
- slides: http://www.slideshare.net/AlexanderUlanov1/a-scalable-implementation-of-deep-learning-on-spark-alexander-ulanov
- mirror: http://pan.baidu.com/s/1jHiNW5C
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
- arxiv: http://arxiv.org/abs/1603.04467
- gitxiv: http://gitxiv.com/posts/57kjddp3AWt4y5K4h/tensorflow-large-scale-machine-learning-on-heterogeneous
Distributed Supervised Learning using Neural Networks
- intro: Ph.D. thesis
- arxiv: http://arxiv.org/abs/1607.06364
Distributed Training of Deep Neuronal Networks: Theoretical and Practical Limits of Parallel Scalability
How to scale distributed deep learning?
- intro: Extended version of paper accepted at ML Sys 2016 (at NIPS 2016)
- arxiv: https://arxiv.org/abs/1611.04581
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
- intro: Tsinghua University & Stanford University
- comments: we find 99.9% of the gradient exchange in distributed SGD is redundant; we reduce the communication bandwidth by two orders of magnitude without losing accuracy
- keywords: momentum correction, local gradient clipping, momentum factor masking, and warm-up training
- arxiv: https://arxiv.org/abs/1712.01887
Distributed learning of CNNs on heterogeneous CPU/GPU architectures
https://arxiv.org/abs/1712.02546
Integrated Model and Data Parallelism in Training Neural Networks
- intro: UC Berkeley & Lawrence Berkeley National Laboratory
- arxiv: https://arxiv.org/abs/1712.04432
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
- intro: ICLR 2018
- intro: we find 99.9% of the gradient exchange in distributed SGD is redundant; we reduce the communication bandwidth by two orders of magnitude without losing accuracy
- arxiv: https://arxiv.org/abs/1712.01887
Projects
Theano-MPI: a Theano-based Distributed Training Framework
CaffeOnSpark: Open Sourced for Distributed Deep Learning on Big Data Clusters
- intro: Yahoo Big ML Team
- blog: http://yahoohadoop.tumblr.com/post/139916563586/caffeonspark-open-sourced-for-distributed-deep
- github: https://github.com/yahoo/CaffeOnSpark
- youtube: https://www.youtube.com/watch?v=bqj7nML-aHk
Tunnel: Data Driven Framework for Distributed Computing in Torch 7
Distributed deep learning with Keras and Apache Spark
- project page: http://joerihermans.com/work/distributed-keras/
- github: https://github.com/JoeriHermans/dist-keras
BigDL: Distributed Deep learning Library for Apache Spark
Videos
A Scalable Implementation of Deep Learning on Spark
Distributed TensorFlow on Spark: Scaling Google’s Deep Learning Library (Spark Summit)
Deep Recurrent Neural Networks for Sequence Learning in Spark (Spark Summit)
Distributed deep learning on Spark
- author: Alexander Ulanov July 12, 2016
- intro: Alexander Ulanov offers an overview of tools and frameworks that have been proposed for performing deep learning on Spark.
- video: https://www.oreilly.com/learning/distributed-deep-learning-on-spark
Blogs
Distributed Deep Learning Reads
https://github.com//tmulc18/DistributedDeepLearningReads
Hadoop, Spark, Deep Learning Mesh on Single GPU Cluster
http://www.nextplatform.com/2016/02/24/hadoop-spark-deep-learning-mesh-on-single-gpu-cluster/
The Unreasonable Effectiveness of Deep Learning on Spark
https://databricks.com/blog/2016/04/01/unreasonable-effectiveness-of-deep-learning-on-spark.html
Distributed Deep Learning with Caffe Using a MapR Cluster

https://www.mapr.com/blog/distributed-deep-learning-caffe-using-mapr-cluster
Deep Learning with Apache Spark and TensorFlow
https://databricks.com/blog/2016/01/25/deep-learning-with-apache-spark-and-tensorflow.html
Deeplearning4j on Spark
http://deeplearning4j.org/spark
Distributed Deep Learning, Part 1: An Introduction to Distributed Training of Neural Networks
GPU Acceleration in Databricks: Speeding Up Deep Learning on Apache Spark
https://databricks.com/blog/2016/10/27/gpu-acceleration-in-databricks.html
Distributed Deep Learning with Apache Spark and Keras
Adversarial Training
Learning from Simulated and Unsupervised Images through Adversarial Training
- intro: CVPR 2017 oral, best paper award. Apple Inc.
- arxiv: https://arxiv.org/abs/1612.07828
The Robust Manifold Defense: Adversarial Training using Generative Models
https://arxiv.org/abs/1712.09196
DeepDefense: Training Deep Neural Networks with Improved Robustness
https://arxiv.org/abs/1803.00404
Low-Precision Training
High-Accuracy Low-Precision Training
- intro: Cornell University & Stanford University
- arxiv: https://arxiv.org/abs/1803.03383
Incremental Training
ClickBAIT: Click-based Accelerated Incremental Training of Convolutional Neural Networks
- arxiv: https://arxiv.org/abs/1709.05021
- dataset: http://clickbait.crossmobile.info/
ClickBAIT-v2: Training an Object Detector in Real-Time
https://arxiv.org/abs/1803.10358
Papers
Understanding the difficulty of training deep feed forward neural networks
- intro: Xavier initialization
- paper: http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf
Domain-Adversarial Training of Neural Networks
- arxiv: https://arxiv.org/abs/1505.07818
- paper: http://jmlr.org/papers/v17/15-239.html
- github: https://github.com/pumpikano/tf-dann
Scalable and Sustainable Deep Learning via Randomized Hashing
Training Deep Nets with Sublinear Memory Cost
- arxiv: https://arxiv.org/abs/1604.06174
- github: https://github.com/dmlc/mxnet-memonger
- github: https://github.com/Bihaqo/tf-memonger
Improving the Robustness of Deep Neural Networks via Stability Training
Faster Training of Very Deep Networks Via p-Norm Gates
Fast Training of Convolutional Neural Networks via Kernel Rescaling
FreezeOut: Accelerate Training by Progressively Freezing Layers
Normalized Gradient with Adaptive Stepsize Method for Deep Neural Network Training
- intro: CMU & The University of Iowa
- arxiv: https://arxiv.org/abs/1707.04822
Image Quality Assessment Guided Deep Neural Networks Training
https://arxiv.org/abs/1708.03880
An Effective Training Method For Deep Convolutional Neural Network
- intro: Beijing Institute of Technology & Tsinghua University
- arxiv: https://arxiv.org/abs/1708.01666
On the Importance of Consistency in Training Deep Neural Networks
- intro: University of Maryland & Arizona State University
- arxiv: https://arxiv.org/abs/1708.00631
Solving internal covariate shift in deep learning with linked neurons
- intro: Universitat de Barcelona
- arxiv: https://arxiv.org/abs/1712.02609
- github: https://github.com/blauigris/linked_neurons
Tools
pastalog: Simple, realtime visualization of neural network training performance
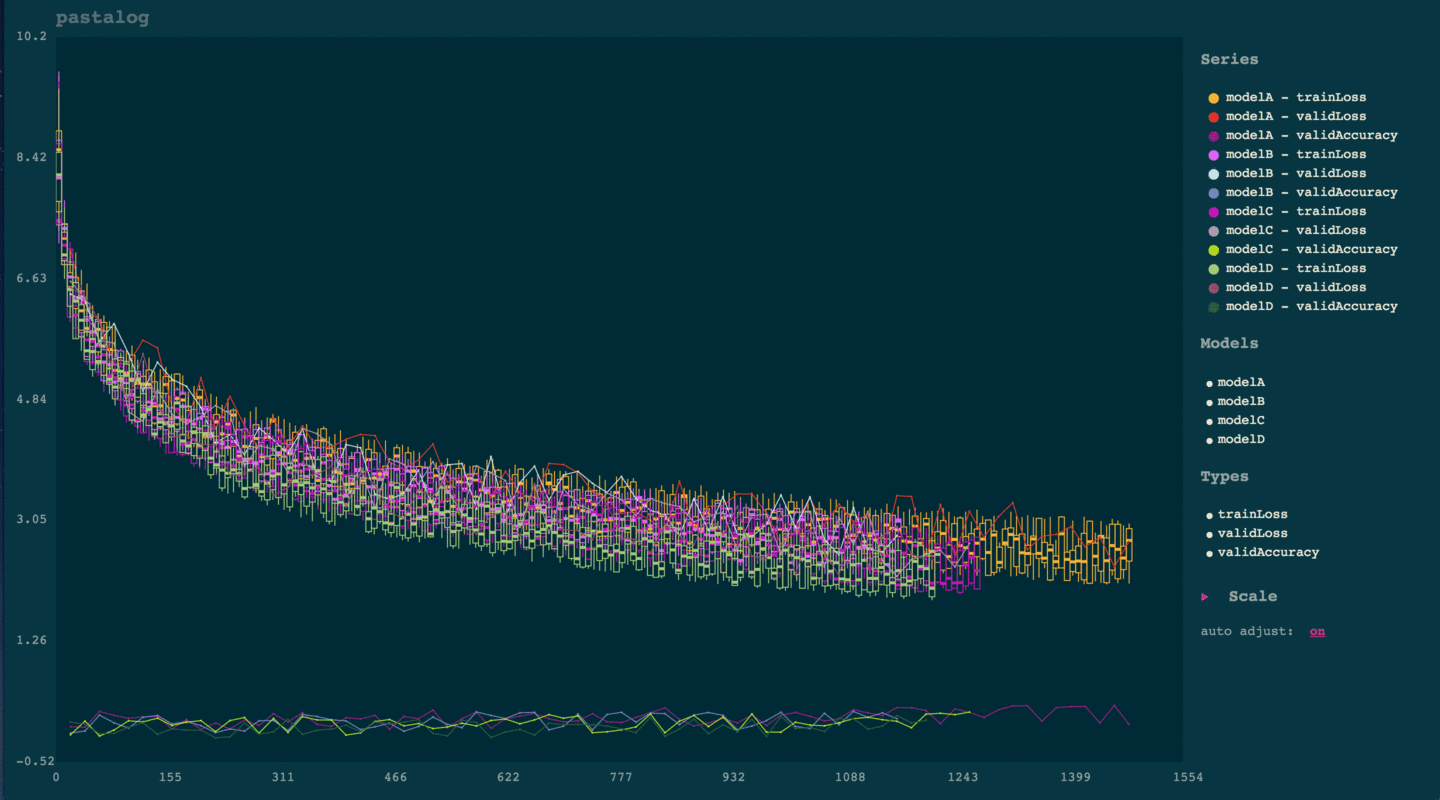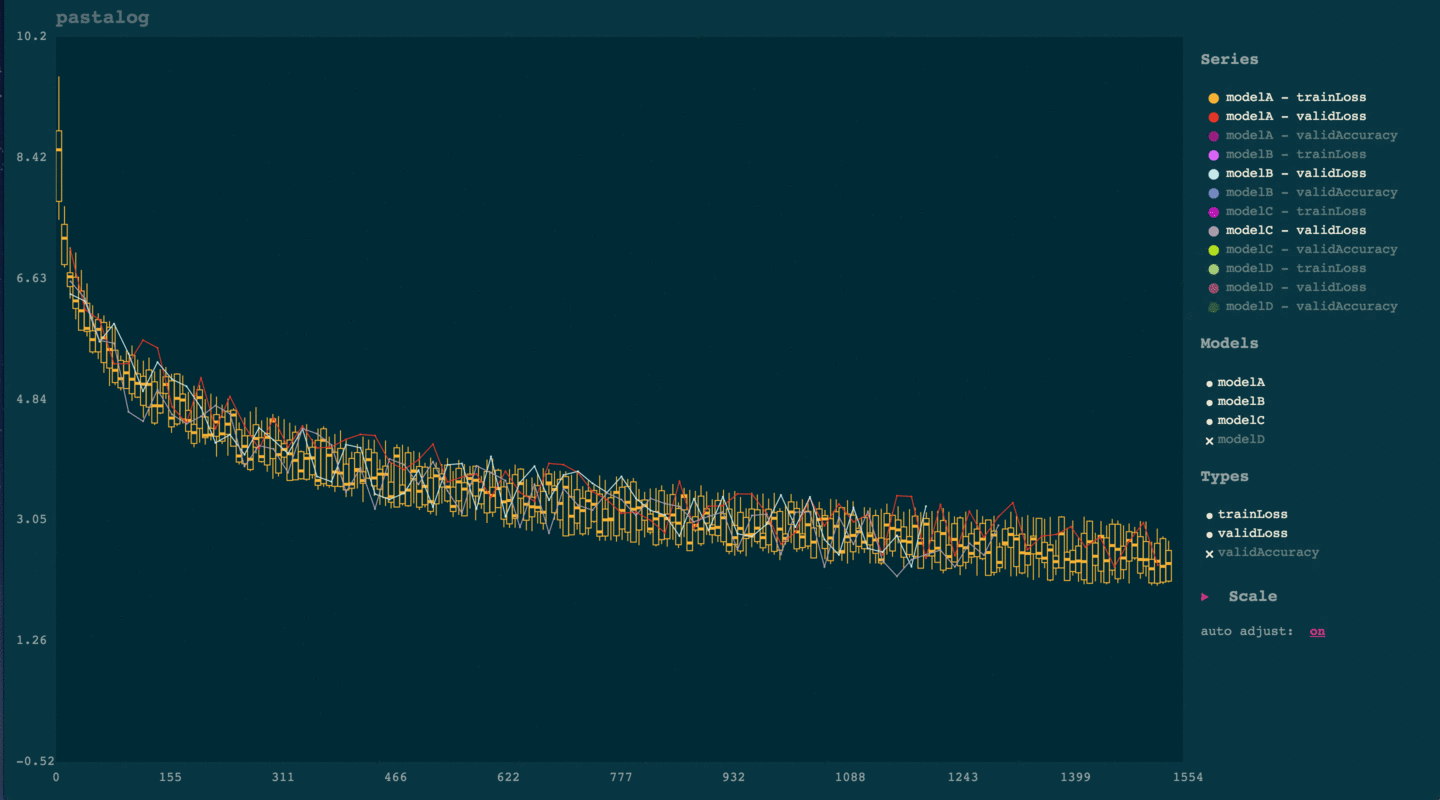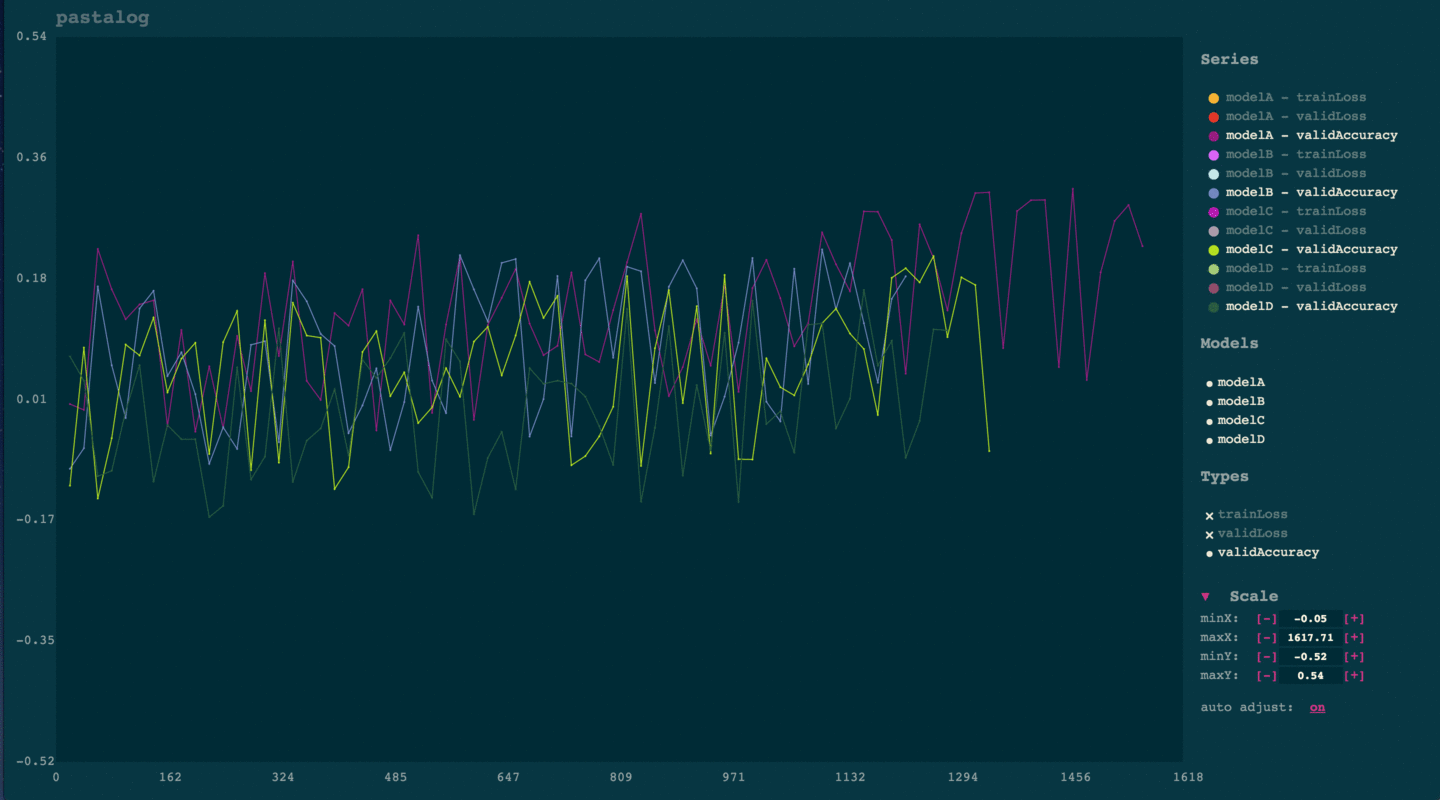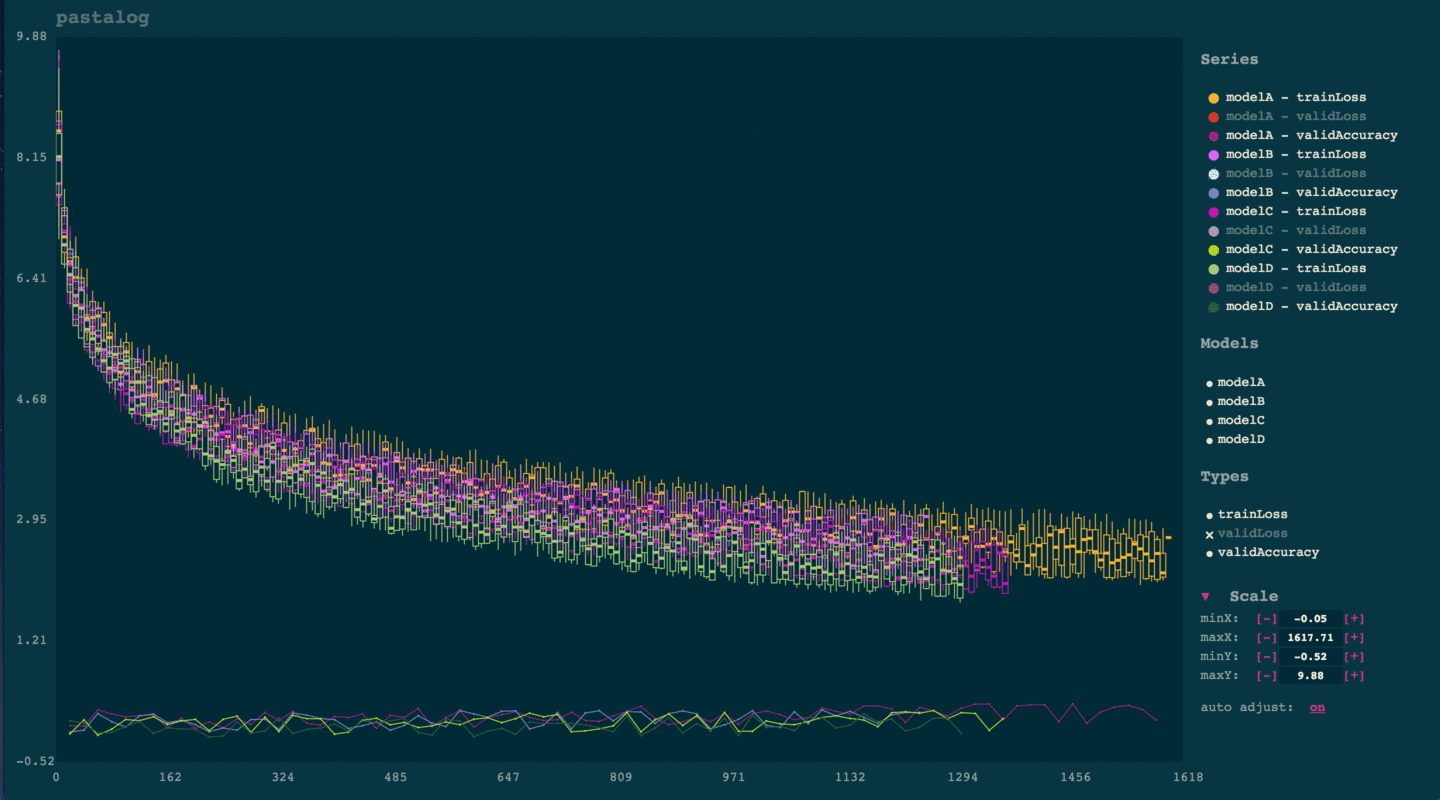
torch-pastalog: A Torch interface for pastalog - simple, realtime visualization of neural network training performance
Blogs
Important nuances to train deep learning models
http://www.erogol.com/important-nuances-train-deep-learning-models/
Train your deep model faster and sharper — two novel techniques
https://hackernoon.com/training-your-deep-model-faster-and-sharper-e85076c3b047
